
Cataloguing Practices in the Age of Linked Open Data: Wikidata and Wikibase for Film Archives
By Adelheid Heftberger and Paul Duchesne
June 2020
1. Introduction
The FIAF Cataloguing Rules For Film Archives from 1991 begins with the words: “This manual consists of a set of rules for cataloguing materials held in moving image archives. Its immediate purpose is to provide a means of facilitating the exchange of information between and among archivists, so that cataloguing records, created in one archive, may be readily interpreted and understood in another”.[1] Obviously the authors did not write these words with Linked Open Data in mind, but what we are doing today in the Cataloguing & Documentation Commission’s Linked Open Data Task Force can be regarded as very much staying true to (and extending) these principles.
Cataloguing is one of the core intellectual tasks in a film archive and will continue to be so for some time. Records are notoriously messy in archival databases and intellectual decisions have to be made frequently. This is especially relevant when it comes to cataloguing different versions of a film work. For a long time archival catalogues were structured in a two-tier hierarchy, which consisted of a filmographic work and the related items held in the collection. Cataloguing therefore has traditionally focused both on gathering filmographic information (like film titles, cast/credits, country of reference and year of reference) as well as holding data regarding the physical objects in their collection, to put it very simply.
This process is time consuming and therefore costly, as has been pointed out in the 1991 FIAF manual: “Although not highly visible, professional cataloging work is expensive, and archivists have long dreamed of being able to avoid duplication of effort by sharing completed cataloging work, thereby reducing costs.”[2] A recent study carried out in German film archives and libraries, investigated the situation in Germany and talked to experts about possible reasons why film archives are not using cataloguing practices like those established in libraries for a long time, e.g. using a union catalogue.[3] The study concludes that it was not so much unwillingness or resistance towards sharing their data, but rather not knowing how to achieve such an ambitious goal, which would ultimately benefit everyone from film archives to users, with only limited resources.
Today, pioneering advances in this area, such as the Joint European Filmography (JEF) initiated in 1992, have been all but completely forgotten. Many of the technical problems that the project faced, as outlined by coordinator Geoffrey Nowell-Smith,[4] could be more easily solved nowadays, such as the issue of different “versions” which has been adequately accounted for with the EN 15907 metadata standard. Also, the internet would provide a much more appropriate (and efficient) access platform than the “reasonably priced” CD Nowell-Smith had envisioned.
Optimistically film archives appear to be putting more effort into advancing the standardisation of metadata in order to be able to share and exchange filmographic information. For example, some of the German archives have engaged in a joint effort to implement the metadata standard EN 15907[5] and publish their holdings on the de-facto national German filmography filmportal[6] over the course of the next couple of years, just to identify one example. From here, it is not hard to envision the creation of a common metadata pool, where authority files are gathered, checked and made available to all contributors. At present, identifying the correct original title of a Czech film from the 1920s is not as simple as one might think, based only on the sources available to an average film archive. For the correct information one just has to turn to the Národní filmový archiv in Prague, who would be able to provide the necessary information with far greater ease and far less hassle.
There have been voices who have suggested that by presenting our data as Linked Open Data, we would encourage solutions to these problems. Linked data is essentially what it sounds like: linking one’s data to someone else’s data, and thus enriching it by connecting together data from diverse sources. The technology behind the semantic web as a means to create these links in a machine-readable way was coined by Tim Berner-Lee: “The Semantic Web isn't just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.”[7] In order to transform information from human-readable into machine-readable data, we have to use a different, highly formalised language based on one or more suitable ontologies. One way of doing this is by creating so-called RDF Triples. RDF stands for Resource Description Framework and is based on the concept of making standardised claims about data relationships by expressing them as “subject - predicate - object” statements.[8] RDF is often stored in relational databases (for example in so-called Triplestores). RDF is usually mentioned in relation with OWL (Web Ontology Language). While RDF is the standard for the basic syntax of the semantic web, OWL is a necessary tool in order to create and publish ontologies. OWL distinguishes between classes, properties and instances. Classes are most generally terms/concepts which can have properties, while instances are individuals of one or more classes. While this may sound very technical and fairly abstract, Wikidata, one of the most successful crowd sourced data initiatives of the last 5 years is based on these structures.
Film archives are only starting to look into LOD, and generally ontologies are not extensively used.[9] TV archives are more active on that field and have developed the EBUCore ontology, an RDF representation of the EBU Class Conceptual Data Models (CCDM), which defines a structured set of audiovisual classes, e.g. “groups of resources, media resources, parts, and media objects, but also locations, events, persons, and organizations”.[10]
In 2015 the FIAF Cataloguing and Documentation Commission started investigating how Linked Open Data could be used in film archives, what the issues were and what advantages adoption would entail.[11] One guiding assumption was that if film archives concentrated on harvesting existing information, improving it along the way if necessary, the time and manpower saved could be better invested in other areas. In this article we would like to present practical experiences gained while looking closer into how platforms built on the same technology as Wikidata can be facilitated both as a data provider as well as a potential aggregator and hub for filmographic information. We see this contribution as a starting point for more debate on how to share and enrich our data, and hope to get more film archives engaged in taking part in this discussion.
2. Wikidata, Wikibase and Filmographic Data
While praiseworthy initiatives from the library domain such as VIAF (Virtual International Authority File)[12] or GND (Gemeinsame Normdatei)[13] can provide film archives with much valuable input, the overlap with filmographic data has unfortunately been minimal. At the other end of the spectrum, user-generated platforms such as the Internet Movie Database and Wikipedia have resulted in literally millions of film-related records, the quality and validity of which can sometimes be disputed, and which are therefore observed with restraint for good reason. While Wikipedia started out as a collection of published texts, Wikidata[14], a related Wikimedia project created in 2012, has been gaining momentum over the last few years and contains many millions of data records across all areas of human knowledge. It acts as the centralised storage location for the structured machine-readable data of its sister projects, including the aforementioned Wikipedia, Wikicommons, Wikisource and others, as well a great deal of data which is unique to that platform. Wikidata runs on software called Wikibase[15], which is notable in that it is possible to create your own custom Wikibase instance at minimal cost and effort, and which allows for specific properties and items which could be considered too specialised for Wikidata.
This means that we can look at the ontology of Wikidata critically, and implement an ontology on our own platform which better reflects the desired cataloguing standards of contemporary film archives. By linking similar properties back to Wikidata we can have the best of both worlds, allowing for a higher level of specification on our own platform, while also allowing the ability to push and pull data between other knowledge bases where desirable.
How does the Wikidata ontology currently relate to film works? It is fairly basic if we compare to traditional film catalogues (specifically when comparing it to EN 15907 later on in the text). Generally there is a single item devoted to each film work, and each of these items is created with a unique identifying code (starting with a Q). Other items (specifically film-related or otherwise) can be linked into this page in the form of "statements" (or "claims"), via a property (P) (for example: "colour technology", "country of origin", "aspect ratio" and "publication date" are all properties of "film" (Q11424)). These properties can also be given further detail in the form of "qualifiers", for example "Vertigo" (Q202548) has a distinct "Germany" (Q183) "publication date" (P577): 3 February 1959.
One of the most important triples in the Wikidata item is the "instance of" (P31) property, which defines the ontological parent of the object (or concept). While many of the film records on Wikidata link back as expected "instances of" (P31) "film" (Q11424), a strange quirk of the model is that this is not always true. For example, "Der letzte Mann/The Last Laugh" (Q258830) is not a "film" (Q11424), but an "instance of" (P31) a "silent film" (Q226730). And this is not applied consistently: "Der Golem/The Golem" (Q1622001) is a "film" (Q11424), despite also being silent. It is also worth noticing that as the scope of Wikidata is intended to include the entire world, records can link back in ontologically curious ways: "silent film" (Q226730) is a subclass of "silence" (Q502261), which is in turn a subclass of "nothing" (Q154242).
How are film works typically represented in Wikidata? Let’s look at how “Chelovek s kinoapparatom/Man with a Movie Camera” (Dziga Vertov, 1929, USSR) is depicted on Wikidata in order to demonstrate its logic:
- Item: “Man With a Movie Camera” (Q829250)
- Additional language labels in many different languages.
- A brief description of the item as “1929 film by Dziga Vertov”, also translated into different languages.
- Instance of (P31): “film” (Q11424) and “silent film” (Q226730)
- Image (P18): frame grab from the film and linked to Wikicommons
- Video (P10): also linked to Wikicommons
- Title (P1476): text in Russian (language information additionally given)
- Genre (P136): “documentary film” (Q93204), “silent film” (Q226730) and “experimental film” (Q790192)
- Author (P50): “Dziga Vertov” (Q55193)[16]
- Country of origin (P 495): “Soviet Union” (Q15180)
- etc.
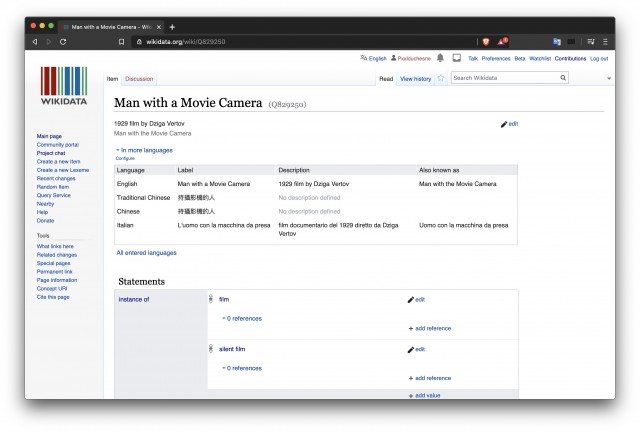
Fig. 1: Wikidata page of “Man with a Movie Camera”.
This is an example of a well populated film record, it should be noted that, as with all filmographies, there are obscure titles which carry almost no attached data. In Wikidata's case this can be quite extreme, existing as only a “link” between a parent Wikipedia page and corresponding IMDb page.
As there are no mandatory data fields and manual editing is possible at any time, Wikidata encourages the voluntary use of references which should be added when editing a Wikidata item. These references can take the form of data sourced from other internet databases, printed resources (as demonstrated in our case study)[17], but also potentially, the examination of physical objects (specifically, film prints).
By way of a comparison, the FIAF Cataloguing handbook lists the following core elements of description, which have been mapped here to relevant Wikidata properties where possible:
1. Film Title (Series/Serial): “title” (P1476)
2. Cast: “cast member” (P161) or “voice actor” (P725)
3. Credits (e.g. Director, Production Company): “director” (P57), “producer” (P162), “screenwriter” (P58), “director of photography” (P344), “film editor” (P1040), “production company” (P272), etc
4. Country Of Reference (e.g. Production): “country of origin” (P495)
5. Original Format, Length, Duration: “duration” (P2047)
6. Original Language: “original language of film or TV show” (P364)
7. Year of Reference: “publication date” (P577)
8. Identifier: various, e.g. “GND ID” (P227), “VIAF ID” (P214), “EIDR Identifier” (P2704), “IMDb ID” (P345)
9. Subject/Genre/Form: “genre” (P136)
10. Content Description: links to Wikipedia pages in different languages[18]
Although, it looks like Wikidata's ontology would allow for most of the desired information, consistent mapping to Wikidata might not be possible, because not every film title is identical when it comes to properties and “instances of” (as has been shown before). An example of a statement which causes confusion within the current Wikidata ontology is the item's “label”. Each item on Wikidata (film or otherwise) carries a “label”, which is a general name referring to the item (and also the first element returned in search results). This “label” is displayed in bold at the top of the page, and occupies a space that would normally be saved for an original film title in a filmography. This is usually the case for Wikidata, although there are also notable collisions between translations of that original title and different distribution titles.
The problem here is that at present there is a lack of consensus regarding whether alternate language “labels” for films of other countries should adopt either the local release title, or the original title translated into that language (where this is not the same thing). An especially interesting example here is films which were released in another country with an altered title, but in the language of the original country (a practice which seems especially popular for US-releases in France). For instance, strictly following the label/language logic of Wikidata, we would expect that the “original title” (Q1294573) and English label for “The Hangover” (Todd Phillips, 2009, US) would be “The Hangover”, the title “valid in place” (P3005) “France” (Q142) would be the French release title “Very Bad Trip”, but the French “label” would be “La gueule de bois” (ie, a literal translation of the original title into the relevant language). This would be controversial, as it would be the primary metadata field against the film on French Wikidata, yet it is a title under which the film was never released. Essentially this is a conflict between following the strict logic of a machine-readable environment, while also allowing for human-readability. Another contentious example would be the English label for “La dolce vita” (Federico Fellini, 1960, IT), which following this logic would be a literal English translation (“The Sweet Life”), but this would be immediately rejected as it would have serious ramifications for searchability. In regards to our own instance of Wikibase this problem could be resolved by universally honoring the original release title of the work, without translation at all, and additional release titles provided within the Wikibase title properties.
As mentioned before, in creating our own (as in film archives) properties and classes for a seperate Wikibase instance, we have the opportunity to link non-controversial mappings (those above), have the ability to include properties for highly specific film data, but should also be aware of areas where the current Wikidata ontology is lacking coherence or consistency, and which could cause problems if naively pushing or pulling statements between the two.
3. The Wikidata/Wikibase ontology compared to EN 15907
Over the past couple of years, a growing number of film archives have adopted the metadata standard EN 15907, produced following a mandate issued by the European Commission in 2015 for the development of a standard for the identification of cinematographic works.[19] As has been mentioned before, one reason for creating a metadata schema specifically for film, was that it proved necessary to represent different versions of films and their related items. Frequently, cataloguers are faced with the task of determining if a print in the archive is actually a different version (variant/manifestation - depending on the 3- or 4-tier hierarchy implemented) of a film work. And if that is already a challenge, because this deserves accurate knowledge of the content and production history of that particular item, how do we then attempt to map versions from different sources in collaborative data exchange projects? Without a doubt, this is one of the major challenges for already existing aggregation projects, like FIAF’s “Treasures from the Film Archives”, Europeana, filmportal etc. Wikidata properties are flat, EN 15907 is hierarchical. How does Wikidata relate to this specific topic and is there a way to differentiate between different versions?
The core question would just be which “properties” (in the Wikidata/Wikibase sense) best describe the relationships expressed in that standard. In regards to “cinematographic work” and “variant”, there might be two options, one “relational” and one “explicit”. In the first case, any film which does not contain the attribute of being a “modified version of” would be assumed to be a “cinematographic work” (ie it is not modified from anything else), but any film entry which had a “modified version of” would be considered as a “variant”.
On the other hand, the explicit path would be to actually have a “EN 15907” property, ready for use in RDF-triple form: eg “Picnic At Hanging Rock (Original Release)” > “EN 15907” > “cinematographic work”; “Picnic At Hanging Rock (Director's Cut)” > “EN15907” > “variant” (and with an additional “qualifier” “variant of” “Picnic At Hanging Rock (Original Release)”). There are clear advantages here, because it removes any ambiguity (ie is the film a “cinematographic work” by inference or just missing data?), and leaves the door open for also using these properties down to the level of actual prints and reels.
As a quick reminder, here is the definition of variant as in the FIAF Cataloguing Manual:
“An entity that may be used to indicate any change to content-related characteristics that do not significantly change the overall content of a Work as a whole. Such Variants can be produced by minor additions, deletions or substitutions to the content. As a general guideline, changes that would result in a different content description should be treated as a separate Work rather than a Variant.”[20]
Typical examples for variants are minor changes in extent/duration, the addition of new footage to a Work, partial alteration of dialogue and/or narration of an existing Work (including the removal and/or addition of dialogue) or removal and/or replacement and/or addition of any one or more of the contributors (e.g., cast and/or crew), but not substantially most, associated with a Work. In order to distinguish different film works, these changes would have to be described with properties like “minor change in extent”, “different cast”, “alteration of dialogue” (these do not exist yet and would need to be defined by the film archival community) and then linked to the film work. The same would have to be done for manifestations, although when looking closer at Wikidata entries, the items mostly already contain information like publication date, duration, language, aspect ratio (which are usually attached to a manifestation). The following figures show the different hierarchy levels (Fig. 2-4) and the related information as depicted in the FIAF Cataloguing Manual.[21]
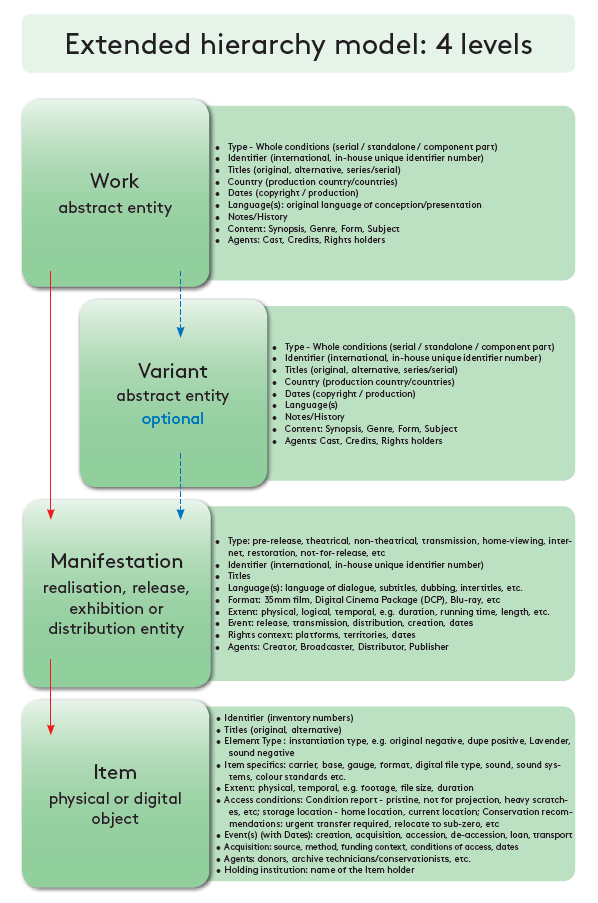


Fig. 2-4: Hierarchy levels and the related information from FIAF Cataloguing Manual
To allow linking with these items careful consideration would have to be made about how best to link a properly implemented EN 15907 tiered Wikibase database with the current Wikidata model, and indeed all other filmographic databases which maintain a similarly flat structure.
4. Case study: Pike-Cooper
Our case study used data sourced from the book Australian Film 1900-1977[22], an indispensable guide to early Australian cinema written by Dr Andrew Pike and Ross Cooper, which features many obscure titles not held by the National Film and Sound Archive of Australia and/or lost works. Despite the book containing extensive filmographic information, in respect to the authors' wishes, and in the interest of testing with a minimal dataset, only the title, year and director data was extracted for use (as well as country, by insinuation).
While the early manifestations of our coding project had been built around the intention of embedding data directly into Wikidata, it soon became apparent that a far more interesting demonstration would be to create our own Wikibase installation. This example was specifically created for the case study, and included interlinking to the relevant Wikidata items as a demonstration of the viability of such a model for linking archival data.
At present the easiest way to install a self-hosted Wikibase instance is via a “Docker” image kindly provided by the Wikimedia Deutschland group.[23] Once the software has installed it is possible to begin building the properties and items which will make up the ontology. The structure can be either as similar or as different from Wikidata as desired, and there are also scripts available which will automatically install all existing Wikidata properties across into the custom Wikibase.[24] Given that our source data was quite minimal, few properties were initially required: an “instance of” (P1) property to distinguish film items from authorities, as well as “title” (P2), “year” (P3), “country of origin” (P4) and “director” (P5) properties. All of these directly correlate to WIkidata properties (as described above), so any pushing or pulling of data between the two platforms would not require any further property mapping. Lastly, a “pike-cooper identifier” (P6) property was added as a linking device back to the source text, as a demonstration for how archival sourced data could link back to original MAM identifiers.
The import of the general film information was performed using an application provided with Wikibase (and also Wikidata) called QuickStatements. This tool allows for the bulk ingest of thousands of semantic triples at a time, including the creation of new records (as can be seen in the examples below). All of the data-parsing between syntaxes was performed in Python, a flexible programming language which has been seeing increasing use within the archival community, given its wide ranging ability to assist with transcoding, metadata and analytics-related tasks.
QuickStatements title creation example:
CREATE
LAST|Len|"Soldiers Of The Cross"
LAST|Den|"1900 film by Joseph Perry and Herbert Booth"
LAST|P1|Q1
LAST|P2|en:"Soldiers Of The Cross"
LAST|P4|Q2
LAST|P3| 1900-01-01T00:00:00Z/9
LAST|P6|"1"
A separate batch of QuickStatements was generated via a similar Python script to create the authority records for bulk ingest.
QuickStatements authority creation example:
CREATE
LAST|Len|"A. C. Tinsdale"
LAST|Den|"Australian Film Director"
Q151|P5|LAST
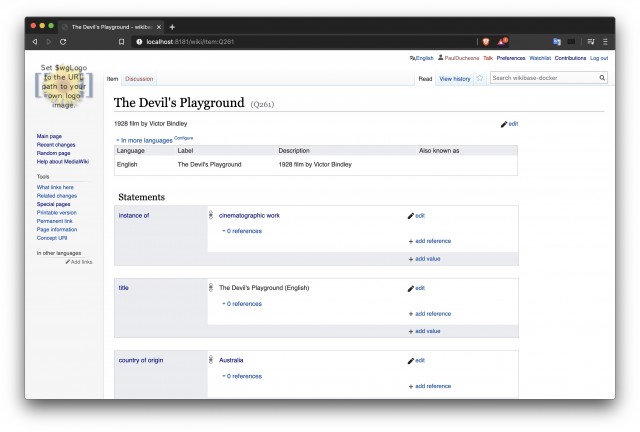
Fig. 5: Wikibase instance of “The Devil’s Playground”
Once the data had been successfully embedded into the Wikibase, it could now be linked to the matching WIkidata items (where existing). An initial difficulty of this task was that this required the local acquisition of all film-related Wikidata data to facilitate matching. Remarkably, the entirety of “current state” Wikidata can be acquired as a single compressed file in JSON format (56 GB at time of writing).[25] However while this file can be downloaded reasonably quickly, it takes a substantial amount of time to parse (more than a week on an entry-level computer). As only around 300,000 of the 81,925,903 Wikidata records are film titles (0.4 %),[26] this is mostly wasted processing time. Another approach was to download data for the 300,000 titles one-at-a-time using SPARQL queries via the Wikidata API, but this proved similarly time-consuming. The solution was ultimately a compromise between the two extremes: by downloading the data in chunks grouped by the Wikidata “year” property (P577) the process takes only a few hours. It should be noted that experiments in pulling down all film related data via a single SPARQL query (in a few minutes) were promising, but only when using a powerful computer (specifically with 64GB or more memory) and it was thought undesirable to make expensive hardware a prerequisite for running the code.
SPARQL example: People who have received Academy Awards and Nobel Prizes:
SELECT DISTINCT ?person ?personLabel
WHERE { ?person wdt:P166/wdt:P31? wd:Q7191 .
?person wdt:P166/wdt:P31? wd:Q19020 .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en" . }} [27]
In regards to the mapping itself, a number of different approaches were trialled, with the most successful in terms of speed and relative accuracy being linked via authority records and their respective filmographies.[28] In the case of Pike-Cooper, there were no pre-existing authority identifiers, as the source material was a printed book, so these had to be artificially generated. Given the limited size of the early Australian cinema industry it was judged appropriate to generate these identifiers based on name overlap (an approach which would cause confusion elsewhere). All of the “year” data was adjusted to accommodate a tolerance of /- 1 to compensate for the common confusion whether to attribute production or release year.
On the Wikidata side, the properties extracted for matching were: “director” (P57), “producer” (P162), “screenwriter” (P58), “director of photography” (P344), “film editor” (P1040), “cast member” (P161) and “voice actor” (P725). A conscious decision was made to enable matching between any role, as there appears to be some confusion as to appropriately classifying director/producer/dop/editor duties for many early, animated and/or experimental works. Also of interest, Wikidata specifically differentiates “actor” (P 161) and “voice actor” (P 725) (ie for an animated film), whereas many filmographies and archival databases do not.
The Levenshtein Distance algorithm[29] was used heavily throughout this process, which results in a mathematical value representing the difference between two strings of characters, and which allowed for the quick identification of likely matches. The strength of combining title and name data into a single function, is that while there may be many similarly titled films, even within the same year, it is unlikely that they will credit similarly named individuals, and furthermore, that those individuals have other similar-named titles in their filmographies. The strength of this process can be seen in the automatic accurate identification of F. W. Thring (Pike-Cooper) and Francis William Thring (Wikidata) as the same person, based only on the overlaps in their filmographies.
Another advantage of this process is that all of the credit and title information can be processed in a single pass, as the film title matches which inform the credit matching are retained as matches in their own right. It should be noted that this is a fundamentally optimistic way of approaching the problem, as the effectiveness and accuracy of the process will only grow as more filmographic data is added into Wikidata. In terms of speed, the matching script ran for around 30 minutes, although this could certainly increase on datasets containing more recent works (as there is more data to process).
The final stage of the test case was to embed the Wikidata identifiers into the Wikibase instance, to facilitate data exchange between the two data sets. At present this is a one-way link, as our test case was transient, but in the future a more formal environment would allow for a persistent identifier to be placed back within Wikidata.
In regards to the results themselves: of the 214 directors who feature in Pike-Cooper, 138 (65%) were correctly matched, 7 (3%) were missed (as manually verified) and 69 (32%) did not exist in Wikidata. A number of the missed cases would have been found if the process had been extended to include more work with string normalization, although a few were simply single-credit directors with film titles which were too radically different to return any sort of reliable match.
Before discussing the matching on film titles it is worth reiterating the constraints of the project and the resulting impact on the identified matches. As the only credit used on the source data was the “director” credit, and the matching algorithm operates based predominantly on name matches, this did lead to some limitations as to the scope of possible matches. To begin with, 17 of the 488 Pike-Cooper do not contain any director information and were not able to be processed at all. Furthermore, even though 478 of the remaining Pike-Cooper films did exist on Wikidata, 60 did not contain any director credit information, so were also not able to return any matches within these constraints. Of the remaining 411 films however, the process performed extremely well, with 393 (96%) correct matches. It should also be highlighted that unlike earlier attempts at a matching process which requires manual verification of “weak” matches, this system is entirely automated and requires no manual checking.
This points to a few possible future paths: obviously, a more extensive source dataset would be preferable, but also a complementary system which flips the algorithm rather than searching for matching names by filmography, searching for titles by unique combinations of credits.
Another option is flipping the primary data source itself, as the script operates on the assumption that one side of the matching process is better populated than the other. This would be true of comparing many film collections with Wikidata, but this relationship would possibly need to be inverted for a highly specialised collection. However, for the sake of demonstration, this method succeeded in providing a completely automated solution, with the potential for extension as required by future requirements.
The code can be found on: https://github.com/paulduchesne/pike-cooper for anyone who is interested.
5. Conclusions and Outlook
In our text we mainly want to both share some practical observations on Wikidata's metadata model and how it relates to film cataloguing, as well as provide some of the experiences made when mapping existing records with data from film historical sources. During our discussions and script-writing, it transpired that Wikibase is gaining some momentum for use with GLAM institutions, such as national libraries in Germany[30] and France. If cultural heritage institutions can have their own database within the Wikimedia framework, that will serve two goals: firstly, ensure control of the data model and data integrity by the collecting institution, and secondly, that data can be pushed and shared easily as a linked open data resource and thus made search- and findable.
It is also possible to move data (or properties) from Wikidata across to one's own Wikibase, in order to copy all of Wikidata's film data (where properties were mapped) - which could be interesting for archives cataloguing many international film works. Wikibase allows for full control of the dataset, e.g. regulations on who can edit the data. It is possible to set up logins for “trusted users” from FIAF archives for example.
The path each archive wants to take will depend very much on the institution's policy when it comes to giving access to data as well as technical and human resources. Not every film archive will be comfortable about pulling filmographic information from Wikidata and/or publishing large datasets on Wikidata themselves. On the other hand, providing data as linked data certainly has advantages if an institution wants to provide more and easier access to their collection and link their holdings with other institutions on the internet (e.g. film related collections in other institutions even outside the film archives circle). The Wikimedia universe is growing fast and provides persistent identifiers which are enriched with other identifiers from other databases - this is what filmportal pursues as well. Information is in machine readable form, which makes data import easier and creating a human readable front can be done with some coding expertise.[31]
Is it feasible for every film archive to build their own Wikibase? Most likely not. But a FIAF Wikibase might be an interesting option for a shared data pool, controlled by FIAF institutions and populated with filmographic and maybe even holdings information.
To sum up, we could see two distinct possible future models - one, a centralised Wikibase instance (aka FIAFDATA), where data will be mapped by FIAF/or a centralised group. The second option, would be to release a github software repository which contains a pre-configured Wikibase Docker image, so that every archive could easily launch their own Wikibase instance with a (FIAF CDC) approved ontology, in the form of predefined properties, a csv template to facilitate contributing archival data, and some script to assist with mapping to shared identifiers (eg Wikidata).
Either of these options would represent a huge step forward in interoperability for archival collection data, and in fact the distinction between the benefits of the two models is small, given that the wonderful thing about Linked Open Data is that it does not matter where data is stored as long as it is both open and linked.
Authors
Dr. Adelheid Heftberger is Head of Film Access at the film department of the German Federal Archive (Berlin). Previously she has held positions at the Brandenburg Center for Media Studies (Potsdam) and the Austrian Film Museum (Vienna) as researcher, curator and archivist. She obtained her PhD in Russian studies and a Masters in Comparative Literature from the University of Innsbruck and Vienna. In 2016 she completed Library and Information Sciences at the Humboldt-University in Berlin. She is also a full member of the Cataloging and Documentation Commission of FIAF and active in the Open Science movement. Contact: adelheidh@gmail.com
Paul Duchesne is the Data Analyst for the National Film and Sound Archive (Canberra). He has an extremely diverse range of archival experience, including data visualisation and analysis, photochemical film preservation, film projection, digital preservation and analogue media conservation. He holds a Bachelor of Arts in Digital Arts from the Australian National University, a Graduate Certificate in Audiovisual Archiving from the Charles Sturt University, and is an active member of the FIAF Working Group for Linked Open Data. Contact: paulduchesne@tuta.io
Notes
[1] Harrison, Harriet W. (ed.) 1991. The FIAF Cataloguing Rules for Film Archives. München, London, New York, Paris: K.G.Saur, p. ix. URL: https://www.fiafnet.org/images/tinyUpload/E-Resources/Commission-And-PIP-Resources/CDC-resources/FIAF_Cat_Rules.pdf
[2] Ibid.
[3] Heftberger, Adelheid. 2017. Wer bringt das Filmerbe zu den Nutzern? Potentielle Synergien in der Erschließung und Vermittlung von Filmwerken zwischen Bibliotheken und Filmarchiven. Berlin: Berliner Handreichungen zur Bibliotheks- und Informationswissenschaft, pp. 49ff. http://edoc.hu-berlin.de/series/berliner-handreichungen/2017-415/PDF/415.pdf.
[4] Nowell-Smith, Geoffrey. 1996. “The Joint European Filmography (JEF),” in Catherine A. Surowiec (ed), The Lumiere Project. The European Film Archives at the Crossroads. Lisbon: The LUMIERE Project, pp. 169-173.
[5] For more information see: http://filmstandards.org/fsc/index.php/EN_15907
[6] For more information see: https://www.filmportal.de/.
[7] See Tim Berners-Lee: Linked Data. 27. Juli 2006. http://www.w3.org/DesignIssues/LinkedData.html
[8] To give an example, an RDF triple can look like this: “Sergej Eisenstein” (subject)> “was born in” (Predicat)> “Riga” (Object). Or: “Sergej Eisenstein” (Subject) > “is director of” (Predicat) > “Bronenosec Potemkin” (Object).
[9] An early example would be the COLLATE project, a project about German censorship: http://www.difarchiv.deutsches-filminstitut.de/collate/index.html.
[10] See: Simou, Nikolaos, Evain, Jean-Pierre, Tzouvaras, Vassilis, Rendina, Marco, Drosopoulos, Nasos, Oomen, Johan. 2012. “Linking Europe’s Television Heritage”. URL: http://www.museumsandtheweb.com/mw2012/papers/linking_europe_s_television_heritage. EBU Core is also linked to Dublin Core.
[11] For the recent activities see a report by Adelheid Heftberger on a workshop in Berlin in 2019 https://www.fiafnet.org/pages/E-Resources/LoD-Task-Force-Workshop-2019.html and the related article in the Journal of Film Preservation: Heftberger, Heftberger. 2019. “Building Resources Together - Linked Open Data for Filmarchives,” In: Journal of Film Preservation 101 (Oct.), pp. 65-73.
[12] For more information see: https://viaf.org/
[13] Integrated Authority File, created by the Deutsche Nationalbibliothek.
[14] For more information see: https://www.wikidata.org/wiki/Wikidata:Main_Page
[15] For more information see: https://en.wikipedia.org/wiki/Wikibase
[16] This use of “author” is highly unusual in a film context.
[17] For more information see: https://www.wikidata.org/wiki/Help:Sources#Books
[18] Fairbairn, Natasha, Pimpinelli, Maria Assunta, Ross, Thelma. 2016. The FIAF Moving Image Cataloguing Manual, p. 5. URL: https://www.fiafnet.org/images/tinyUpload/E-Resources/Commission-And-PIP-Resources/CDC-resources/20160920 Fiaf Manual-WEB.pdf.
[19] See Ross, Thelma, Balzer, Detlev, McConnachie, Stephen. 2013. “The EN 15907 moving image metadata schema standard and its role in a digital asset management infrastructure,” In: Journal of Digital Media Management, Vol. 2, 3 (2013), pp. 251-262.
[20] FIAFCataloguing Manual, p. 20.
[21] Ibid, p. 7-9.
[22] For more information see: https://www.roninfilms.com.au/video/2221/0/2245.html
[23] For more information see: https://github.com/wmde/wikibase-docker
[24] For more information see: https://github.com/stuppie/wikibase-tools
[25] For more information see: https://dumps.wikimedia.org/wikidatawiki/entities/
[26] “Film titles” defined as instance of, or instance of subclass of “film” (Q11424).
[27] https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/queries/examples
[28] The credit for this concept should go directly to Georg Eckes (Bundesarchiv, Berlin), who mentioned it in one of our early Skype conversations on the subject.
[29] For more information see: https://en.wikipedia.org/wiki/Levenshtein_distance
[30] For more information see: https://blog.wikimedia.de/2020/03/04/wikibase-and-gnd/
[31] For more information see: https://labs.loc.gov/work/experiments/pnp-wikidata-tool/

